- Download PDF of V3
- V1 - Introduction and Management
- V2 - Near Term
- V3 - Mid to Far Term
- V4 - Interoperability Profiles and Guidance
- V5 - Design Rules

1.3. Cloud Computing
88. The "Cloud" in Cloud computing describes a combination of inter-connected networks. This technology area focuses on breaking up a task into sub-tasks. The sub-tasks are then executed simultaneously on two or more computers that are communicating with each other over the “Cloud”. Later, the completed sub-tasks are reassembled to form the completed original main task. There are many different types of distributed computing systems and many issues to overcome in successfully designing one. Many of these issues deal with accommodating a wide-ranging mix of computer platforms with assorted capabilities that could potentially be networked together
89. Implications: The main goal of a cloud computing system is to connect users and resources in a transparent, open, and scalable way. Ideally this arrangement is drastically more fault tolerant and more powerful than many combinations of stand-alone computer systems. If practiced in a NATO environment, member nations would consume their IT services in the most cost-effective way, over a broad range of services (for example, computational power, storage and business applications) from the "cloud", rather than from on-premises equipment.
1.3.1. Platforms
90. Cloud-computing platforms have given many businesses flexible access to computing resources, ushering in an era in which, among other things, startups can operate with much lower infrastructure costs. Instead of having to buy or rent hardware, users can pay for only the processing power that they actually use and are free to use more or less as their needs change. However, relying on cloud computing comes with drawbacks, including privacy, security, and reliability concerns.
1.3.1.1. Amazon's Elastic Compute Cloud (EC2)
91. Amazon Elastic Compute Cloud (Amazon EC2) is a web service that provides resizable compute capacity in the cloud. It is designed to make web-scale computing easier for developers. If your application needs the processing power of 100 CPUs then you scale up your demand. Conversely, if your application is idle then you scale down then amount of computing resources that you allocate.
92. Status:The first company to successfully levearge the excess computing resources from its primary bussiness. Currently, CPU cycles and storage are at pennies per hour or GB.
1.3.1.2. Microsoft's Azure Services Platform
93. Windows Azure is a cloud services operating system that serves as the development, service hosting and service management environment for the Azure Services Platform. Windows Azure provides developers with on-demand compute and storage to host, scale, and manage Web applications on the Internet through Microsoft data centers.
94. Status: During the Community Technology Preview (CTP) developers invited to the program, which includes all attendees of the Microsoft Professional Developers Conference 2008 (PDC), receive free trial access to the Azure Services Platform SDK, a set of cloud-optimized modular components including Windows Azure and .NET Services, as well as the ability to host their finished application or service in Microsoft datacenters.
1.3.1.3. Google App Engine
95. Google App Engine enables you to build web applications on the same scalable systems that power Google applications. App Engine applications are easy to build, easy to maintain, and easy to scale as your traffic and data storage needs grow. With App Engine, there are no servers to maintain: You just upload your application, and it's ready to serve to your users. Google App Engine applications are implemented using the Python programming language.
96. Status: Currently in the preview release stage. You can use up to 500MB of persistent storage and enough CPU and bandwidth for about 5 million page views a month for free. Later on if you want additional computing resources, you will have to purchase it.
1.3.2. Grid Computing
97. Grid computing is the collective name of technologies that attempt to combine a set of distributed nodes into a common resource pool. The term grid computing stems from an analogy with electric power grids that combine a large set of resources (power plants, transformers, power lines) into simple well defined product (the power outlet) that the user can use without having to know the details of the infrastructure behind it.
98. Typical for grid computing is also that it offers a framework for management of node memberships, access control, and life cycle management. Common applications of grid computing allow well defined organisations to share computational resources or storage resources so that resources may be used efficiently and resource demanding tasks can be performed that would otherwise have required large specialised and/or local investments.
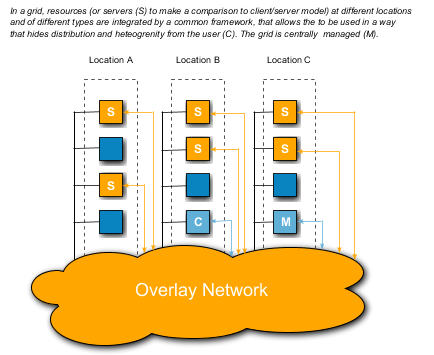
99. While some grid computing systems have been designed for a specific purpose, some standards for Grid infrastructure have also evolved that make the task of setting up a Grid easier and provide a common interface to application developers. Such standardisation efforts have resulted in Globus Toolkit [19] and OGSA (Open Grid Services Architecture) [21].
100. The Global Grid Forum (GGF) [20] is a set of working groups where much work on grid computing standardisation is ongoing, and that also is behind the OGSA standard. Their web site is a good source of information about ongoing work in the field and examples of grid projects.
1.3.2.1. Globus Toolkit
101. Globus Toolkit [19] offers tools and APIs for building secure grid infrastructures. It offers a secure infrastructure (GSI) on top of which support for resource management, information services, and data management is provided. It is being developed by Globus Alliance [18], and is among other applications being used as a foundation for implementation of OGSA.
1.3.2.2. OGSA
102. OGSA [20] (developed by the Global Grid Forum, GGF [20]) builds on a combination of Globus Toolkit [19] (developed by the Globus Alliance [18]) and Web service technologies to model and encapsulate resources in the Grid. A number of special Web service interfaces are defined by OGSA that support service management, dynamic service creation, message notification, and service registration. A number of implementations of OGSA have been made, including for example OGSI (Open Grid Services Infrastructure) and WSRF (Web Services Resource Framework, developed by OASIS [17]). Today, WSRF is the chosen basis for further development of OGSA
1.3.2.3. OSGi
103. OSGi is a standard for a framework for remotely manageable networked devices [5]. Applications can be securely provisioned to a network node running an OSGi framework during runtime and thus provides the possibility to dynamically manage the services and functionality of the network node. The OSGi model is based upon a service component architecture, where all functionality in the node is provided as "small" service components (called bundles). All services are context aware of each other and heavily adapt their functionality depending on what other services are available. Services must degrade gracefully when the services they depend upon are not available in the framework. These network nodes are designed to reliably provide their services 24/7/365. Adding an OSGi Service Platform to a networked node/device adds the capability to manage the life cycle of the software components in the device. Adding new services thus makes it more future proof and gives the node flexibility.
104. OSGi adopts a SOA based approach where all bundles deployed into an OSGi framework are described using well defined service interfaces. The bundle uses the framework's name service for publishing offered services and to retrieve services needed by the bundle itself. OSGi works well together with other standards and initiatives for example Jini or Web Services. OSGi is also an example of a technology where integration is carried out in the Java environment but the actual implementation of the services can be written in other languages, such as C.
1.3.3. Decentralised Computing
105. Another trend in distributed system is to decrease the dependence on centralised resources. A centralised resource is typically some service of function implemented by dedicated nodes in the distributed system that many of or all other nodes depend on to perform their own services or functions. Examples of such services are shared databases, network routing and configuration functions, and name or catalogue services. Obviously, this may cause dependability problems as the centralised server becomes a potential single point of failure (). From some points of view, decentralisation (i.e To decrease the dependence single nodes), is therefore a property to strive for. However, decentralisation may also result in a (sometimes perceived) loss of control that fits poorly with traditional ways of thinking of, for example, security. Decentralisation can thus have a rather long-reaching impact on the way distributed systems are designed.
106. Taken to its extreme, decentralisation strives for distributed systems where all nodes are considered equal in all respects (except of course their performance and capacity), i.e., all nodes are considered to peers. This is the foundation to peer-to-peer (P2P) systems, which will be discussed later. In such systems, decentralisation is realised by offering mechanisms to maintain a global shared state that is not stored by any single node.
1.3.3.1. Peer-to-Peer (P2P)
107. Peer-to-peer, or P2P for short, is a technology trend that has received much attention in recent years. Unfortunately, much of this attention has been oriented towards questionable applications of P2P, such as illegal file sharing, rather than towards its merits as a technology that addresses important problems with traditional distributed systems.
108. The fundamental idea behind P2P is, as is implied by its name, that all participating nodes in a distributed system shall be treated as peers, or equals. This is a clear deviation from the client/server concept, where some nodes play a central role as servers and other nodes play a role as clients. In those systems, the server nodes become critical for the system function, and thus need to be dependable, highly accessible, and dimensioned to handle a sometimes unpredictable workload. Obviously this may make a server node both a performance bottleneck and a dependability risk. P2P addresses such problems.
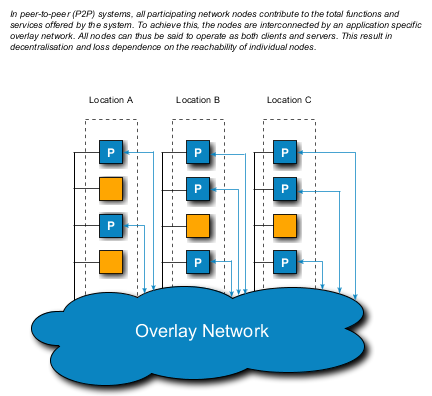
109. The fundamental important property of many P2P applications is that they allow storage of named objects, such as files, services, or database entries, to be spread over all nodes in a system instead of having to store and access them on centralised server nodes. Object names can be numbers or character strings; whichever is appropriate for the applications. Once stored in the system, any node can access a named object just by knowing its name. This means that a P2P system can have a global shared state that does not depend on any centralised node.
110. While in principle avoiding a centralised solution, many early P2P systems, such as the Napster file sharing system actually relied on some central functions in order to implement the mapping from object names to object locations. However, in later generations of P2P decentralisation has been taken another step further, by the introduction of overlay networks, earlier in this report mentioned as a form of virtual networks.
111. With an overlay network, a distributed means of finding the node that is responsible for storing an object with a given name is provided. Typically the set of all possible object names, called the name space, is divided into subsets such that each node becomes responsible for one subset of the name space. This means that the need for centralised resources is completely avoided. For a node to become part of a P2P system, i.e. To join the overlay network, all that is needed is knowledge of any other node already part of the system. As nodes join and leave the system, the responsibility for name space subsets is automatically redistributed.
112. The development of overlay network based P2P systems has been driven by a striving to improve scalability, guarantees, and robustness. Today, a logarithmic logical scalability can be achieved, which means that to find a given node from any other node in the system requires at most logk(N) node-to-node messages to be sent, where k is some constant and N is the maximum number of nodes in the system. Note, however, that this scalability measure does not automatically translate into an exact measure of the actual time it takes to send a message between two nodes as this time will depend also on the distribution of nodes on the underlying physical network.
113. The scalability issue has been addressed by a number of proposed P2P implementation techniques developed within academic research projects such as Chord [13], Pastry [14], and Tapestry [15]. However, scalability has been taken yet another step further by the DKS system developed at the Swedish Institute of Computer Science (SICS. In DKS, the amount of administrative traffic required to keep track of nodes in the overlay network is significantly reduced, and dimensioning parameters of the system can be fine-tuned in a very general framework (that actually treats the other mentioned techniques as special cases) so as to improve the practical scalability.
114. Another important aspect of P2P systems is also the guarantees that can be given that any named object stored in the systems also can found. Such guarantees have improved over the P2P technology generations, and 100% guarantees can now be given by the DKS system assuming that there are no errors such as physical communication failures that make nodes unreachable. As intermittent or lasting communication failures must be expected in any practical system, techniques for improving the fault tolerance by means of replication of data have been investigated and are now being included into the general frameworks of P2P technologies.
115. However, practical applications of new P2P technologies like DKS in distributed systems need to be investigated in order to determine how well scalability and robustness functions in practise given the impact of underlying infrastructure and application properties. An example of an ongoing such project investigates the properties of a DKS based implementation of central service in the OpenSIS standard [16].
116. To summarise, P2P technologies have matured into a practical way of organising distributed systems in a decentralised way that is both highly scalable and reliable. Excellent reviews and descriptions of P2P technologies can be found in [1], [2], and [3].
117. Status: Currently the advantages of P2P technologies (pooling computing power, pooling bandwidth of the participants, and elimination of the server/client distinction) don't outweigh the disadvantages (legal obstacles, and security vulnerabilities)